介绍 Prometheus Agent 模式:一种高效、云原生的指标转发方式
2021年11月16日作者 Bartlomiej Plotka (@bwplotka)
Bartek Płotka 自 2019 年起担任 Prometheus 维护者,同时也是 Red Hat 的首席软件工程师。他是 CNCF Thanos 项目的合著者、CNCF 大使以及 CNCF TAG Observability 的技术负责人。业余时间,他与 O'Reilly 合作撰写一本名为《Efficient Go》的书。本文仅代表我个人观点!
我个人之所以热爱 Prometheus 项目,以及我加入团队的众多原因之一,是该项目对其目标的专注。Prometheus 始终致力于在提供务实、可靠、廉价且极具价值的基于指标的监控方面不断突破。Prometheus 极其稳定和强大的 API、查询语言和集成协议(例如 Remote Write 和 OpenMetrics )为云原生计算基金会(CNCF)的指标生态系统在这些坚实的基础上发展提供了可能。因此,许多令人惊叹的事情发生了。
- 我们可以看到社区为几乎所有事物都开发了 exporter,用于获取指标,例如容器 、eBPF 、Minecraft 服务器统计数据 ,甚至还有园艺中植物的健康状况 。
- 如今,大多数人都期望云原生软件拥有一个可供 Prometheus 抓取的 HTTP/HTTPS
/metrics端点。这个概念最初在谷歌内部秘密开发,并由 Prometheus 项目在全球范围内推广开来。 - 可观测性的范式已经转变。我们看到 SRE 和开发人员从第一天起就严重依赖指标,这提高了软件的弹性、可调试性以及数据驱动的决策能力!
最终,我们几乎看不到没有运行 Prometheus 的 Kubernetes 集群。
Prometheus 社区的高度专注也促进了其他开源项目的发展,这些项目将 Prometheus 的部署模型扩展到单节点之外(例如 Cortex 、Thanos 等)。更不用说云服务商也采纳了 Prometheus 的 API 和数据模型(例如 Amazon Managed Prometheus 、Google Cloud Managed Prometheus 、Grafana Cloud 等)。如果你要问 Prometheus 项目如此成功的唯一原因,那就是:让监控社区专注于重要的事情。
在这篇(冗长的)博文中,我想介绍一种名为“Agent”的 Prometheus 新运行模式。它直接内置于 Prometheus 二进制文件中。Agent 模式禁用了 Prometheus 的一些常规功能,并对二进制文件进行了优化,使其专门用于抓取指标并远程写入到其他位置。引入一种减少功能的模式,反而开启了新的使用范式。在这篇博文中,我将解释为什么它对于 CNCF 生态系统中的某些部署来说是一个颠覆性的改变。我对此感到非常兴奋!
转发用例的历史
Prometheus 的核心设计自项目诞生以来一直未变。受谷歌的 Borgmon 监控系统 的启发,你可以在你想要监控的应用旁部署一个 Prometheus 服务器,告诉 Prometheus 如何访问它们,并让它定期抓取这些应用的指标当前值。这种采集方法通常被称为“拉模型”(pull model),它是使 Prometheus 轻量且可靠的核心原则。此外,它使应用埋点和 exporter 变得极其简单,因为它们只需提供一个简单的人类可读的 HTTP 端点,其中包含所有被追踪指标的当前值(以 OpenMetrics 格式)。所有这些都无需复杂的推送基础设施和繁琐的客户端库。总的来说,一个简化的典型 Prometheus 监控部署如下所示:
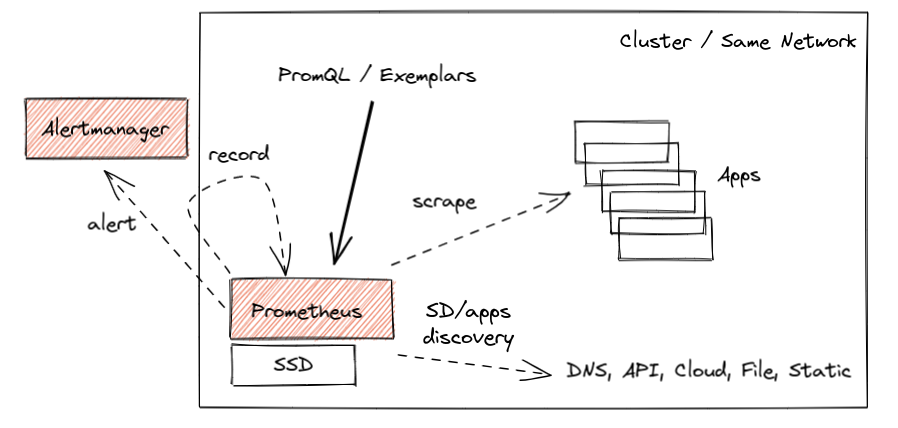
这种方式效果很好,多年来我们已经见证了数百万个成功的部署案例,处理着数千万个活跃的时间序列。其中一些部署的数据保留时间更长,比如两年左右。所有这些部署都允许查询、告警和记录对集群管理员和开发人员都有用的指标。
然而,云原生世界在不断成长和演变。随着托管 Kubernetes 解决方案的增长以及集群可以在几秒钟内按需创建,我们现在终于能够将集群视为“牛”(cattle),而不是“宠物”(pets)(换句话说,我们不太关心它们的单个实例)。在某些情况下,一些解决方案甚至不再有集群的概念,例如 kcp 、Fargate 和其他平台。

另一个有趣的用例是边缘集群或网络的概念。随着电信、汽车和物联网设备等行业采用云原生技术,我们看到越来越多资源受限的小型集群。这迫使所有数据(包括可观测性数据)都必须传输到远程、更大的对应方,因为几乎没有任何东西可以存储在这些远程节点上。
这意味着什么?这意味着监控数据必须以某种方式在*全局*层面进行聚合、呈现给用户,有时甚至需要存储。这通常被称为全局视图(Global-View)功能。
简单地想,我们可以通过两种方式实现这一点:要么将 Prometheus 部署在全局层面,跨越远程网络抓取指标;要么从应用程序直接将指标推送到中央位置进行监控。让我解释一下为什么这两种方法通常都是*非常*糟糕的主意。
🔥 跨网络边界抓取指标可能会成为一个挑战,因为它会在监控管道中引入新的未知因素。本地拉取模型让 Prometheus 能够确切地知道指标目标出现问题的原因和时间。也许它宕机了、配置错误、重启了、响应太慢(例如 CPU 饱和)、服务发现失败、我们没有访问凭证,或者只是 DNS、网络或整个集群都出了问题。如果将抓取器放在网络之外,我们可能会因为与单个目标无关的抓取不可靠性而丢失部分信息。此外,如果网络暂时中断,我们还可能完全失去重要的可见性。请不要这样做,不值得。(
🔥 直接从应用程序将指标推送到某个中央位置同样糟糕。特别是当你监控一个庞大的集群时,如果你没有看到来自远程应用程序的指标,你几乎一无所知。是应用程序宕机了吗?是我的接收管道出问题了吗?也许是应用程序授权失败?也许是它无法获取我远程集群的 IP 地址?也许是它太慢了?也许是网络中断了?更糟糕的是,你甚至可能不知道某些应用程序目标的数据丢失了。而且你也没有获得太多好处,因为你需要追踪所有应该发送数据的东西的状态。这样的设计需要仔细分析,因为它太容易导致失败了。
注意无服务器函数和短生命周期的容器通常是我们考虑从应用推送作为解决方案的场景。然而,在这种情况下,我们谈论的是我们可能希望聚合成更长生命周期时间序列的事件或指标片段。这个话题在这里 有讨论,欢迎贡献并帮助我们更好地支持这些用例!
Prometheus 引入了三种方式来支持全局视图的用例,每种方式都有其优缺点。让我们简要回顾一下。它们在下图中以橙色显示。
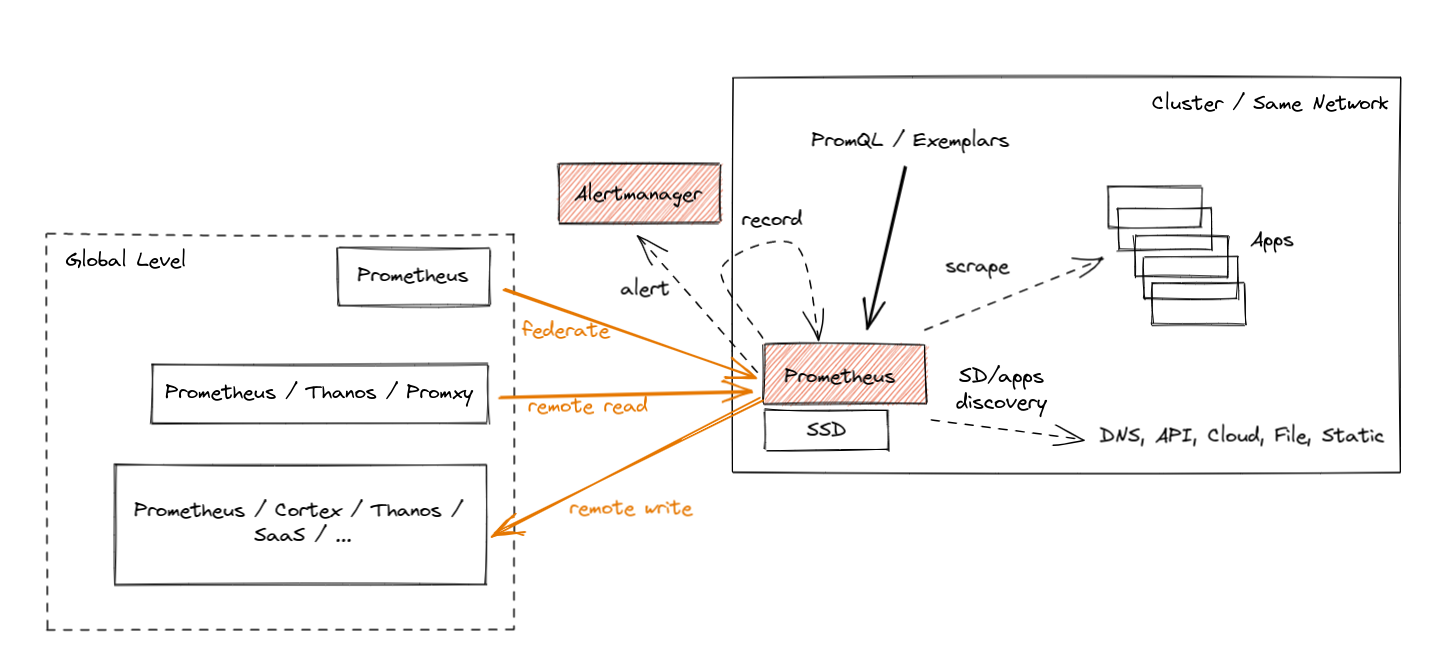
- 联邦(Federation)是为聚合目的引入的第一个功能。它允许一个全局级别的 Prometheus 服务器从一个叶节点 Prometheus 抓取一部分指标。这种“联邦”抓取减少了跨网络的一些未知因素,因为联邦端点暴露的指标包含了原始样本的时间戳。然而,它通常会因为无法联邦所有指标以及在较长的网络分区(数分钟)期间会丢失数据而受到影响。
- Prometheus Remote Read 允许从远程 Prometheus 服务器的数据库中选择原始指标,而无需直接进行 PromQL 查询。你可以在全局级别部署 Prometheus 或其他解决方案(例如 Thanos),对这些数据执行 PromQL 查询,同时从多个远程位置获取所需的指标。这非常强大,因为它允许你将数据“本地”存储,并在需要时才访问。不幸的是,它也有缺点。如果没有像 Query Pushdown 这样的功能,在极端情况下,我们可能需要拉取数GB的压缩指标数据来回答一个查询。此外,如果发生网络分区,我们将暂时失明。最后但同样重要的是,某些安全准则不允许入口流量,只允许出口流量。
- 最后,我们有 Prometheus Remote Write,这似乎是目前最受欢迎的选择。由于 Agent 模式专注于 Remote Write 的用例,让我们更详细地解释一下。
远程写入 (Remote Write)
Prometheus Remote Write 协议允许我们将 Prometheus 收集的全部或部分指标转发(流式传输)到远程位置。你可以配置 Prometheus 将一些指标(如果需要,可以包含所有元数据和 exemplars!)转发到一个或多个支持 Remote Write API 的位置。实际上,Prometheus 同时支持接收和发送 Remote Write,所以你可以在全局级别部署一个 Prometheus 来接收数据流并进行跨集群数据聚合。
虽然官方的 Prometheus Remote Write API 规范尚在审查阶段 ,但生态系统已将 Remote Write 协议作为默认的指标导出协议。例如,Cortex、Thanos、OpenTelemetry 以及 Amazon、Google、Grafana、Logz.io 等云服务都支持通过 Remote Write 接收数据。
Prometheus 项目还为其 API 提供了官方的合规性测试,例如,为提供 Remote Write 客户端功能的解决方案提供了 remote-write 发送方合规性测试 。这是快速判断你是否正确实现该协议的绝佳方式。
通过这种抓取器流式传输数据,可以将指标数据存储在中心化位置,从而实现全局视图用例。这也实现了关注点分离,这在应用程序由不同团队管理,而不是由可观察性或监控管道团队管理时非常有用。此外,这也是希望为客户减轻尽可能多工作的供应商选择 Remote Write 的原因。
等一下,Bartek。你刚才提到直接从应用程序推送指标不是最好的主意!
是的,但最棒的是,即使使用 Remote Write,Prometheus 仍然使用拉取模型从应用程序收集指标,这让我们能够了解这些不同的故障模式。之后,我们将样本和序列进行批处理,并将数据导出、复制(推送)到 Remote Write 端点,从而限制了中心点监控的未知因素数量!
值得注意的是,实现一个可靠且高效的远程写入并非易事。Prometheus 社区花费了大约三年时间才打造出一个稳定且可扩展的实现。我们多次重构了 WAL(预写日志),增加了内部队列、分片、智能退避等功能。所有这些都对用户隐藏,用户可以享受到将大量指标存储在中心化位置的高性能流式传输。
动手实践 Remote Write 示例:Katacoda 教程
所有这些在 Prometheus 中都不是新功能。我们中的许多人已经在使用 Prometheus 抓取所有必需的指标,并将其全部或部分远程写入到其他位置。
如果你想亲身体验远程写入功能,我们推荐从 Prometheus 远程写入指标到 Thanos 的 Katacoda 教程 ,它解释了 Prometheus 将所有指标转发到远程位置所需的所有步骤。它是**免费**的,只需注册一个账户即可享受教程!🤗
请注意,此示例使用接收模式下的 Thanos 作为远程存储。如今,你可以使用许多其他与远程写入 API 兼容的项目。
那么,如果远程写入运行良好,我们为什么还要为 Prometheus 添加一个特殊的 Agent 模式呢?
Prometheus Agent 模式
从 Prometheus v2.32.0(下一个版本)开始,每个人都可以使用实验性的 --enable-feature=agent 标志来运行 Prometheus 二进制文件。如果你想在发布前试用,请随时使用 Prometheus v2.32.0-beta.0 或使用我们的 quay.io/prometheus/prometheus:v2.32.0-beta.0 镜像。
Agent 模式针对远程写入用例优化了 Prometheus。它禁用了查询、告警和本地存储,并用一个定制的 TSDB WAL 取而代之。其他一切保持不变:抓取逻辑、服务发现和相关配置。如果你只想将数据转发到远程 Prometheus 服务器或任何其他兼容 Remote-Write 的项目,它可以作为 Prometheus 的直接替代品。本质上,它看起来是这样的:
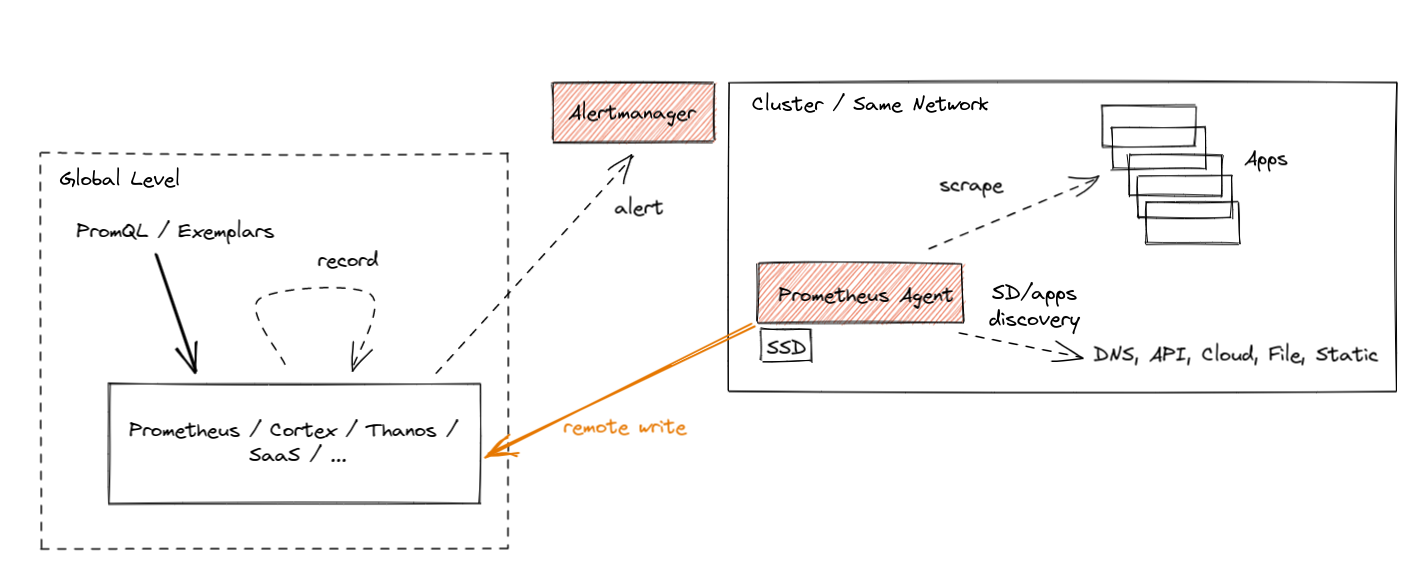
Prometheus Agent 最好的部分是它内置于 Prometheus 中。相同的抓取 API、相同的语义、相同的配置和发现机制。
如果你计划不在本地查询或告警数据,而是将指标流式传输到外部,使用 Agent 模式有什么好处?有以下几点:
首先是效率。我们定制的 Agent TSDB WAL 在成功写入后会立即删除数据。如果无法连接到远程端点,它会将数据临时保存在磁盘上,直到远程端点恢复在线。目前这仅限于两小时的缓冲,与非 Agent 模式的 Prometheus 类似,希望很快能解除限制 。这意味着我们不需要在内存中构建数据块,也不需要为了查询目的维护一个完整的索引。从根本上说,在类似情况下,Agent 模式使用的资源只是普通 Prometheus 服务器的一小部分。
这种效率重要吗?是的!正如我们所提到的,对于某些部署,边缘集群上使用的每一GB内存和每一个CPU核心都至关重要。另一方面,使用指标进行监控的范式如今已经相当成熟。这意味着,以相同的成本,你能传输的指标越相关、基数越高,就越好。
注意随着 Agent 模式的引入,原始的 Prometheus 服务器模式仍然是推荐的、稳定和维护的模式。Agent 模式与远程存储结合带来了额外的复杂性。请谨慎使用。
其次,新的 Agent 模式的好处在于它使得采集的水平扩展变得更容易。这是我最兴奋的一点。让我解释一下原因。
梦想:自动扩展的指标采集
一个真正的自动扩展抓取解决方案需要基于指标目标的数量以及它们暴露的指标数量。我们需要抓取的数据越多,我们就自动部署越多的 Prometheus 实例。如果目标数量或它们的指标数量减少,我们就可以缩减并移除一些实例。这将消除手动调整 Prometheus 大小的负担,并避免在集群暂时较小时为 Prometheus 过度分配资源。
仅使用 Prometheus 服务器模式很难实现这一点。这是因为服务器模式下的 Prometheus 是有状态的。任何收集到的数据都原封不动地保留在一个地方。这意味着缩减过程需要在终止前将收集的数据备份到现有实例。然后我们还会遇到抓取重叠、误导性陈旧标记等问题。
除此之外,我们还需要一些能够聚合所有实例样本的全局视图查询(例如 Thanos Query 或 Promxy)。最后但同样重要的是,服务器模式下 Prometheus 的资源使用量不仅仅取决于采集。还有告警、记录规则、查询、压缩、远程写入等,这些可能需要更多或更少的资源,而与指标目标的数量无关。
Agent 模式从根本上将发现、抓取和远程写入功能转移到一个独立的微服务中。这使得运营模型可以只专注于采集。因此,Agent 模式下的 Prometheus 或多或少是无状态的。是的,为了避免指标丢失,我们需要部署一个 HA agent 对并为它们附加持久化磁盘。但从技术上讲,如果我们有数千个指标目标(例如容器),我们可以部署多个 Prometheus agent,并安全地更改哪个副本抓取哪些目标。这是因为最终所有样本都将被推送到同一个中央存储。
总的来说,Agent 模式下的 Prometheus 使得基于 Prometheus 的抓取能力可以轻松地进行水平自动扩展,从而能够应对指标目标的动态变化。这绝对是我们未来将与 Prometheus Kubernetes Operator 社区共同探讨的方向。
现在让我们来看看 Prometheus 中 agent 模式当前实现的状态。它是否已经可以投入使用了?
Agent 模式已在大规模场景下得到验证
Prometheus 的下一个版本将包含 Agent 模式作为一项实验性功能。标志、API 和磁盘上的 WAL 格式可能会发生变化。但 благодаря Grafana Labs 的 开源工作,该实现的性能已经经过了实战检验。
我们的 Agent 定制 WAL 的最初实现是受当前 Prometheus 服务器的 TSDB WAL 启发的,由 Robert Fratto 在 2019 年创建,并得到了 Prometheus 维护者 Tom Wilkie 的指导。它随后被用于开源的 Grafana Agent 项目中,并被许多 Grafana Cloud 客户和社区成员使用。鉴于该解决方案的成熟度,是时候将该实现捐赠给 Prometheus 以实现原生集成和更广泛的采用。Robert (Grafana Labs) 在 Srikrishna (Red Hat) 和社区的帮助下,将代码移植到了 Prometheus 代码库,并于两周前合并到了 main 分支!
捐赠过程相当顺利。由于一些 Prometheus 维护者之前在 Grafana Agent 项目中为这段代码做过贡献,而且新的 WAL 受到了 Prometheus 自己的 WAL 的启发,所以对于现有的 Prometheus TSDB 维护者来说,接手全面维护并不困难!Robert 加入 Prometheus 团队担任 TSDB 维护者也确实帮了大忙(恭喜!)。
现在,让我们来解释一下如何使用它!(
如何详细使用 Agent 模式
从现在开始,如果你显示 Prometheus 的帮助输出(--help 标志),你应该会看到或多或少如下的内容:
usage: prometheus [<flags>]
The Prometheus monitoring server
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
(... other flags)
--storage.tsdb.path="data/"
Base path for metrics storage. Use with server mode only.
--storage.agent.path="data-agent/"
Base path for metrics storage. Use with agent mode only.
(... other flags)
--enable-feature= ... Comma separated feature names to enable. Valid options: agent, exemplar-storage, expand-external-labels, memory-snapshot-on-shutdown, promql-at-modifier, promql-negative-offset, remote-write-receiver,
extra-scrape-metrics, new-service-discovery-manager. See https://prometheus.net.cn/docs/prometheus/latest/feature_flags/ for more details.由于 Agent 模式受功能标志保护,如前所述,请使用 --enable-feature=agent 标志以 Agent 模式运行 Prometheus。现在,其余的标志要么是服务器和 Agent 模式共用的,要么是仅用于特定模式的。你可以通过检查标志帮助字符串的最后一句来确定哪个标志适用于哪种模式。“Use with server mode only”表示它仅用于服务器模式。如果你没有看到这样的提及,则表示该标志是共享的。
Agent 模式接受与普通模式相同的抓取配置,包括相同的发现选项和远程写入选项。
它还提供了一个禁用了查询功能的 Web UI,但会像普通的 Prometheus 服务器一样显示构建信息、配置、目标和服务发现信息。
动手实践 Prometheus Agent 示例:Katacoda 教程
与 Prometheus remote-write 教程类似,如果你想亲身体验 Prometheus Agent 的功能,我们推荐Thanos Katacoda 的 Prometheus Agent 教程 ,它解释了运行 Prometheus Agent 是多么简单。
总结
希望你觉得这很有趣!在这篇文章中,我们探讨了出现的新用例,例如:
- 边缘集群
- 访问受限的网络
- 大量的集群
- 临时的和动态的集群
然后我们解释了新的 Prometheus Agent 模式,它允许将抓取到的指标高效地转发到 remote write 端点。
一如既往,如果你有任何问题或反馈,请随时在 GitHub 上提交工单或在邮件列表中提问。
这篇博文是 CNCF、Grafana 和 Prometheus 协同发布的一部分。欢迎阅读 CNCF 的公告 以及关于作为 Prometheus Agent 基础的 Grafana Agent 的文章 。