Scalefastr 访谈
2018 年 2 月 8 日作者 Brian Brazil
在我们的 Prometheus 用户系列访谈中,我们继续邀请了 Scalefastr 的 Kevin Burton,他将与我们谈谈他们是如何使用 Prometheus 的。
您能介绍一下自己以及 Scalefastr 的业务吗?
我叫 Kevin Burton,是 Scalefastr 的首席执行官。我的背景是分布式系统,之前我经营着一家名为 Datastreamer 的公司,该公司构建了一个 PB 级别的分布式社交媒体爬虫和搜索引擎。
在 Datastreamer,我们遇到了基础设施的可扩展性问题,并基于 Debian、Elasticsearch、Cassandra 和 Kubernetes 搭建了一个高性能集群。
我们发现,许多客户也在为他们的基础设施而苦恼,我很惊讶他们在 AWS 和 Google Cloud 上托管大量内容需要支付如此高昂的费用。
我们持续评估了在云上运行的成本,对我们来说,托管成本大约是我们目前支付费用的 5-10 倍。
我们决定基于开源和云原生技术,如 Kubernetes、Prometheus、Elasticsearch、Cassandra、Grafana、Etcd 等,推出一个新的云平台。
我们目前正在为几个 PB 级别的客户提供托管服务,并计划在本月对我们的新平台进行软启动。
在使用 Prometheus 之前,您的监控体验是怎样的?
在 Datastreamer,我们发现指标是我们能够快速迭代的关键。对平台的可观测性成为了我们所推崇的东西,并且我们集成了像 Dropwizard Metrics 这样的工具,以便轻松地为我们的平台开发分析功能。
我们构建了一个基于 KairosDB、Grafana 和我们自己(简单的)可视化引擎的平台,这个平台在很长一段时间里都运行得非常好。
我们发现 KairosDB 的主要问题在于其采用率以及客户对 Prometheus 的需求。
此外,Prometheus 的一个优点是支持由项目本身或社区实现的导出器 (exporters)。
使用 KairosDB 时,我们常常需要费力地构建自己的导出器。与 Prometheus 相比,KairosDB 已有导出器的可能性要低得多。
例如,KairosDB 支持 CollectD,但在 Debian 中支持得并不好,而且 CollectD 存在一些实际的 bug,导致它在生产环境中无法可靠地工作。
而使用 Prometheus,你可以很快地启动并运行(系统安装相当容易),而且为你的平台找到现成导出器的可能性非常高。
此外,我们预计一旦有了像 Scalefastr 这样将其集成为标准化、受支持产品的托管平台,客户的应用程序将开始在 Prometheus 指标上实现标准化。
了解应用程序的性能至关重要,而 Prometheus 的高可扩展性是实现这一点的必要条件。
你们为什么决定研究 Prometheus?
我们最初很好奇其他人是如何监控他们的 Kubernetes 和容器应用程序的。
容器的主要挑战之一是它们可以快速地出现和消失,留下了需要分析的日志和指标数据。
当我们看到人们成功地在生产环境中使用 Prometheus,并结合了容器优先的架构,以及其对导出器和仪表盘的支持后,我们清楚地认识到应该研究将 Prometheus 作为我们的分析后端。
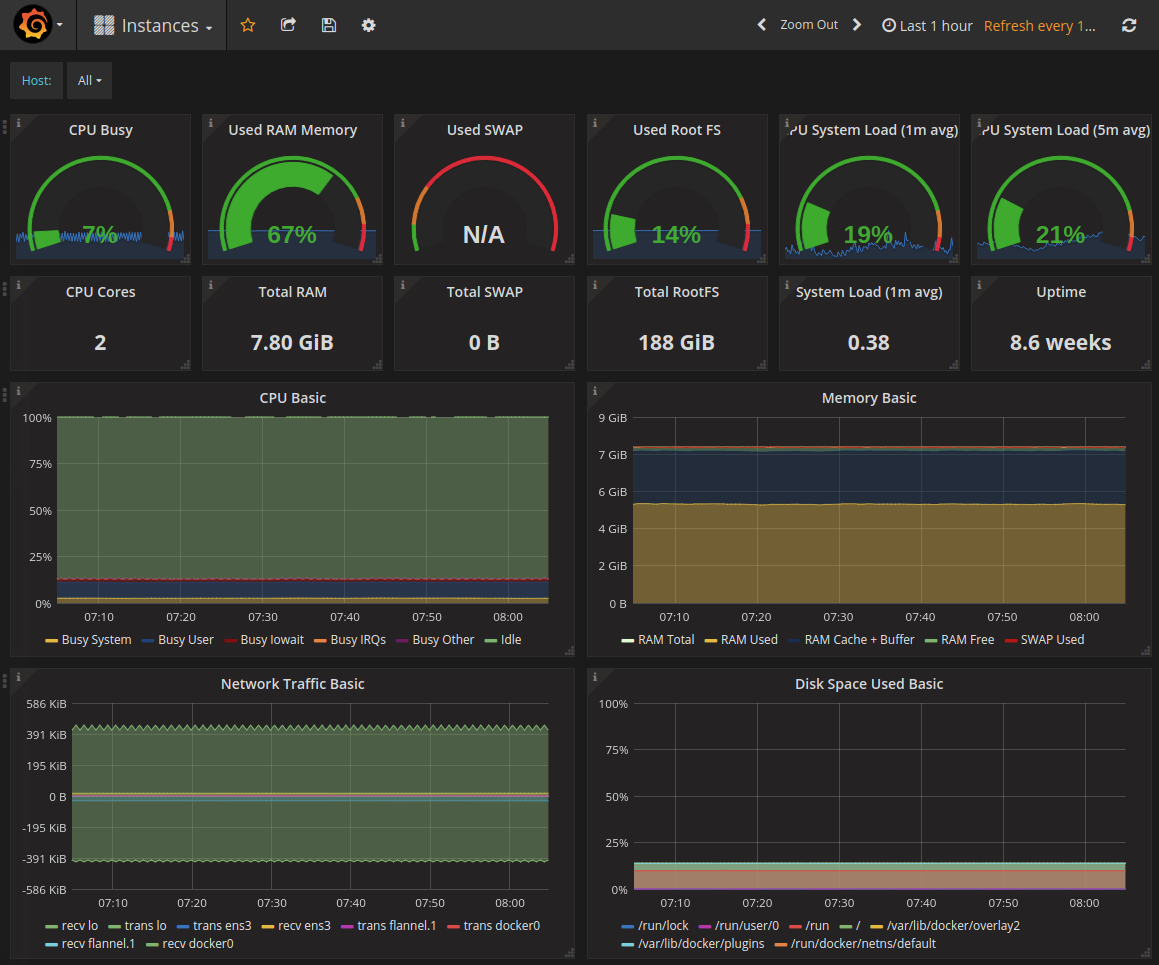
你们是如何过渡的?
由于 Scalefastr 是一个全新的环境,这次转型对我们来说几乎是无痛的。
其架构大部分是全新的,几乎没有什么限制因素。
我们的主要目标是在裸金属上部署,但在现有的标准化硬件之上构建云功能。
我们的想法是让我们集群中的所有分析都由 Prometheus 支持。
我们为客户提供他们自己的“管理”基础设施,其中包括 Prometheus、Grafana、Elasticsearch 和 Kibana,以及一个 Kubernetes 控制平面。我们使用 Ansible 来编排这个系统,它负责处理初始的机器设置(ssh、核心 Debian 软件包等)和基线配置。
然后,我们部署 Prometheus、所有客户配置所需的导出器,以及 Grafana 的仪表盘。
我们发现一个有些问题的地方是,Grafana.com 上的一些仪表盘是为 Prometheus 1.x 编写的,无法顺利地移植到 2.x。事实证明,2.x 系列中只有少数函数不存在了,许多仪表盘只需稍作调整即可。此外,一些仪表盘是为早期版本的 Grafana 编写的。
为了帮助解决这个问题,我们本周宣布了一个项目,旨在为 Prometheus 改进和标准化仪表盘 ,这些仪表盘适用于 Cassandra、Elasticsearch、操作系统以及 Prometheus 本身等工具。我们已经将这个项目开源,并于上周发布到了 Github 。
我们希望这能让其他人更容易地迁移到 Prometheus。
我们想要改进的一件事是,让它能与我们的 Grafana 后端自动同步,同时也将这些仪表盘上传到 Grafana.com。
我们还发布了我们的 Prometheus 配置,以便标签能与我们的 Grafana 模板正确配合工作。这让你可以通过一个下拉菜单来选择更具体的指标,如集群名称、实例名称等。
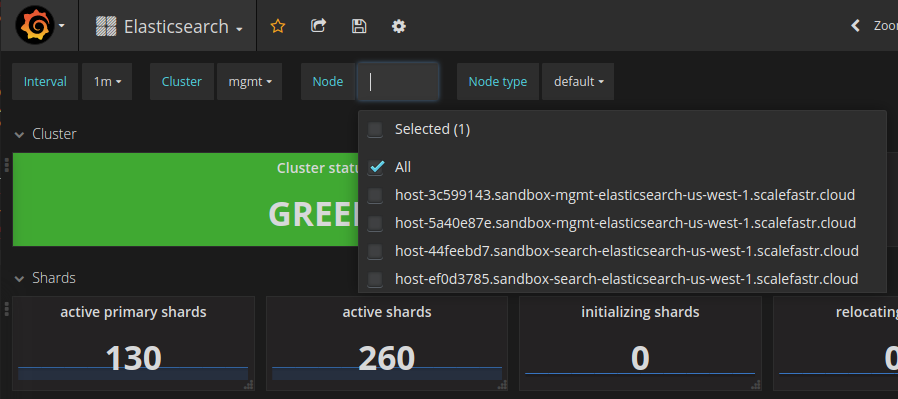
切换后你们看到了哪些改进?
部署的简易性、高性能和标准化的导出器让我们很容易地完成了转换。此外,后端配置相当简单(基本上就是守护进程本身),并且没有太多复杂的活动部件,这也让我们轻松地做出了决定。
您认为 Scalefastr 和 Prometheus 的未来会是怎样?
目前,我们直接在裸金属上部署 Elasticsearch 和 Cassandra。我们正在努力将它们直接运行在 Kubernetes 的容器中,并致力于使用容器存储接口(CSI)来实现这一点。
在我们能做到这一点之前,我们需要让 Prometheus 的服务发现功能正常工作,这是我们还没有尝试过的东西。目前我们是通过 Ansible 来部署和配置 Prometheus 的,但随着工作负载的变化,容器可能会随时出现和消失,这种方式显然无法扩展(甚至无法工作)。
我们也在努力改进标准的仪表盘和告警功能。我们希望增加的一个功能(也许是以容器的形式)是支持基于霍尔特-温特斯 (Holt-Winters) 预测的告警。
这基本上能让我们在严重的性能问题发生之前进行预测。而不是等到出现问题(比如磁盘空间耗尽)后才采取行动来纠正。
在某种程度上,Kubernetes 帮助解决了这个问题,因为我们可以根据一个阈值(watermark)向集群中添加节点。一旦资源利用率过高,我们就可以进行自动扩容。
我们对 Prometheus 的未来感到非常兴奋,特别是现在我们正在推进 2.x 系列,而且 CNCF 的协作似乎也进展顺利。