iAdvize 访谈
2017 年 5 月 17 日作者 Brian Brazil
在我们的 Prometheus 用户系列访谈中,来自 iAdvize 的 Laurent COMMARIEU 将继续为我们讲述他们是如何用 Prometheus 替换掉旧有的 Nagios 和 Centreon 监控系统的。
您能介绍一下 iAdvize 是做什么的吗?
我是 Laurent COMMARIEU,iAdvize 的一名系统工程师。我在公司 60 人的研发部门里一个 5 人组成的系统工程师团队工作。我们的主要工作是确保应用程序、服务以及底层系统的正常运行。我们与开发人员合作,确保他们的代码能以最简单的方式部署到生产环境,并在每个步骤中提供必要的反馈。这正是监控的重要性所在。
iAdvize 是一个全栈式对话式商务平台。无论客户使用何种沟通渠道(聊天、电话、视频、Facebook Pages、Facebook Messenger、Twitter、Instagram、WhatsApp、短信等),我们都为品牌提供一种简单的方式来集中与客户互动。我们的客户遍布 40 个国家,涉及电子商务、银行、旅游、时尚等行业 。我们是一家拥有 200 名员工的国际公司,在法国、英国、德国、西班牙和意大利都设有办事处。我们在 2015 年筹集了 1600 万美元。
在使用 Prometheus 之前,您的监控体验是怎样的?
我于 2016 年 2 月加入 iAdvize。在此之前,我曾在专门从事网络和应用监控的公司工作。我们当时使用的开源软件包括 Nagios 、Cacti 、Centreon 、Zabbix 、OpenNMS 等,以及一些非免费软件,如 HP NNM 、IBM Netcool suite 、BMC Patrol 等。
iAdvize 过去将监控工作委托给外部供应商。他们使用 Nagios 和 Centreon 来确保 24/7 全天候监控。这套工具在传统的静态架构(裸金属服务器,无虚拟机,无容器)下运行良好。为了完善这个监控栈,我们还使用了 Pingdom 。
随着我们将单体应用转向微服务架构(使用 Docker),并计划将当前工作负载迁移到基础设施云提供商,我们需要对监控拥有更多的控制权和灵活性。与此同时,iAdvize 招聘了 3 名新员工,使基础设施团队从 2 人增加到 5 人。使用旧系统,在 Centreon 中添加一些新指标至少需要几天甚至一周的时间,并且成本很高(时间和金钱)。
你们为什么决定研究 Prometheus?
我们知道 Nagios 之类的工具不是一个好的选择。Prometheus 在当时是冉冉升起的新星,我们决定对其进行概念验证(PoC)。Sensu 最初也在我们的考虑名单上,但 Prometheus 似乎在我们的使用场景中更有前景。
我们需要一个能够与我们的服务发现系统 Consul 集成的工具。我们的微服务已经有了 /health 路由;增加一个 /metrics 端点很简单。对于我们使用的几乎所有工具,都有可用的 exporter(MySQL、Memcached、Redis、nginx、FPM 等)。
理论上看起来很不错。
你们是如何过渡的?
首先,我们必须说服开发团队(40 人),让他们相信 Prometheus 是完成这项工作的正确工具,并且他们需要在自己的应用程序中添加 exporter。于是,我们对 RabbitMQ 做了一个小演示,我们安装了一个 RabbitMQ exporter,并构建了一个简单的 Grafana 仪表盘,向开发人员展示使用情况指标。我们还编写了一个 Python 脚本来创建一些队列并发布/消费消息。
当他们看到队列和消息实时出现时,都感到非常惊艳。在此之前,开发人员无法访问任何监控数据。Centreon 的访问权限受到我们基础设施提供商的限制。如今,iAdvize 的每个人都可以使用 Grafana,通过 Google Auth 集成进行身份验证。上面有 78 个活跃账户(从开发团队到 CEO 都有)。
在我们开始使用 Consul 和 cAdvisor 监控现有服务后,我们监控了容器的实际存在情况。之前它们是通过 Pingdom 检查来监控的,但这还不够。
我们用 Go 开发了几个自定义的 exporter,用于从我们的数据库(MySQL 和 Redis)中抓取一些业务指标。
很快,我们就能用 Prometheus 替换掉所有旧的监控系统了。
切换后你们看到了哪些改进?
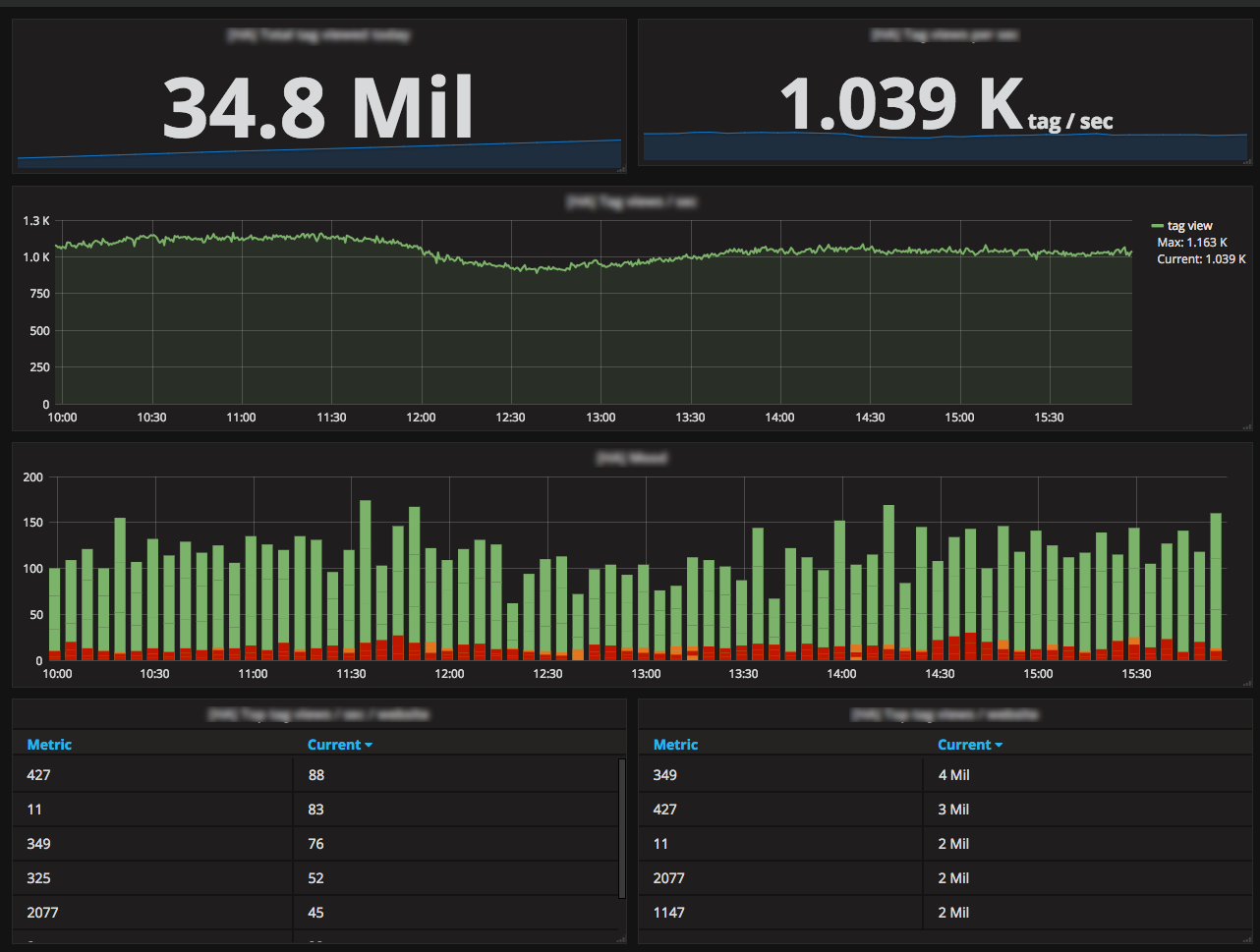
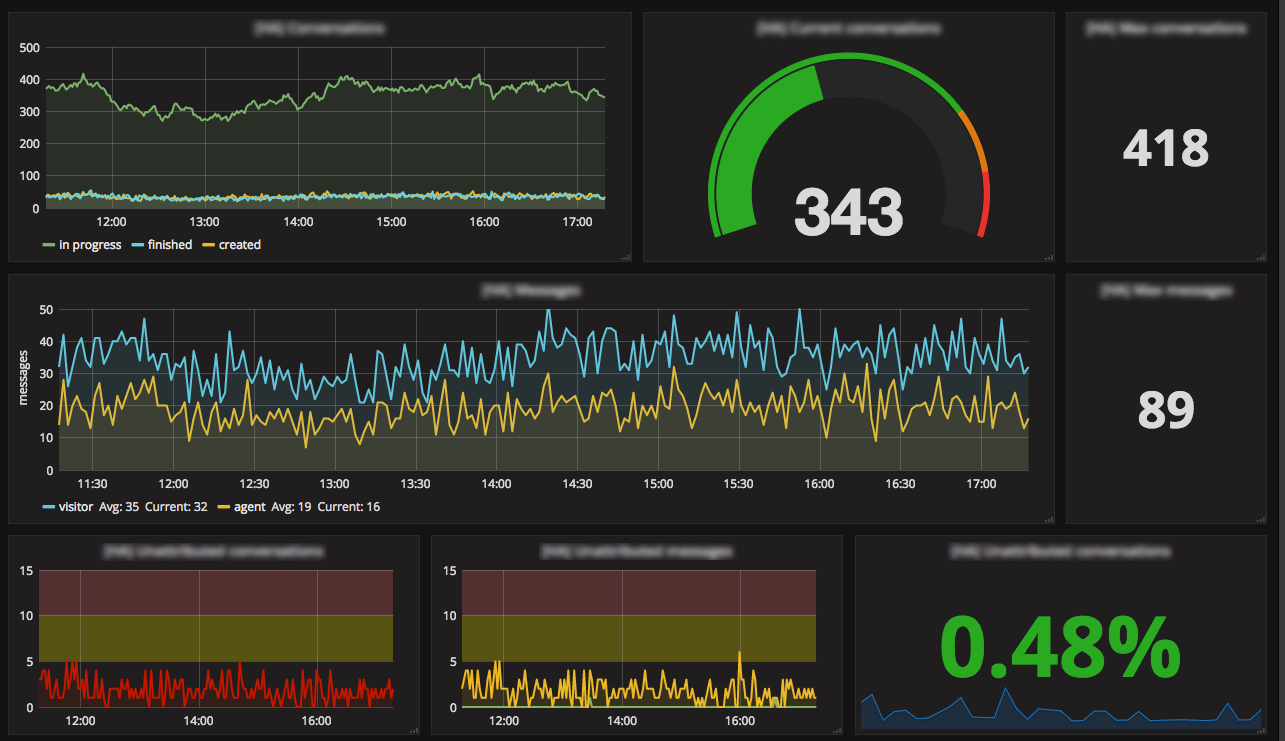
业务指标变得非常受欢迎,在促销期间,每个人都连接到 Grafana,看看我们是否会打破某些记录。我们监控同时进行的对话数量、路由错误、在线客服数量、加载 iAdvize 标签的访客数量、我们 API 网关的调用次数等。
我们花了一个月的时间来优化我们的 MySQL 服务器,分析基于 Newrelic exporter 和 [Percona dashboard for grafana] (https://github.com/percona/grafana-dashboards )。这是一次真正的成功,让我们能够发现效率低下的问题并进行优化,使数据库大小减少了 45%,峰值延迟降低了 75%。
有很多可以说的。我们知道某个 AMQP 队列是否没有消费者,或者是否正在异常地堆积。我们知道容器何时重启。
这种可见性简直太棒了。
这还只是针对旧平台。
越来越多的微服务将被部署到云上,而 Prometheus 正被用来监控它们。我们使用 Consul 来注册服务,并使用 Prometheus 来发现指标路由。一切都运行得非常顺利,我们能够构建一个包含大量关键业务、应用和系统指标的 Grafana 仪表盘。
我们正在使用 Nomad 构建一个可扩展的架构来部署我们的服务。Nomad 在 Consul 中注册健康的服务,通过一些标签重写,我们能够筛选出那些带有“metrics=true”标签的服务。这为我们在部署监控时节省了大量时间。我们几乎什么都不用做 ^^。
我们还使用了 EC2 服务发现。这对于自动伸缩组非常有用。我们对实例进行伸缩和回收,而它们已经被监控了。再也不用等待我们的外部基础设施提供商来注意生产环境中发生了什么。
我们使用 alertmanager 通过短信或发送到我们的 Flowdock 来发送一些警报。
您认为 iAdvize 和 Prometheus 的未来会是怎样?
- 我们正在等待一种简单的方法来为我们的容量规划添加一个可扩展的长期存储。
- 我们有一个梦想,希望有一天我们的自动伸缩能由 Prometheus 的警报来触发。我们想构建一个基于响应时间和业务指标的自主系统。
- 我曾经使用过 Netuitive ,它有一个很棒的异常检测功能,带有自动关联分析。如果 Prometheus 也能有类似的功能就太好了。