ShuttleCloud 访谈
2016 年 9 月 7 日作者 Brian Brazil
继续我们的 Prometheus 用户系列访谈,本期 ShuttleCloud 将分享他们是如何开始使用 Prometheus 的。来自 ShuttleCloud 的 Ignacio 也在 PromCon 2016 上解释了为什么 Prometheus 对你的小型初创公司有好处 。
ShuttleCloud 是做什么的?
ShuttleCloud 是全球最具扩展性的电子邮件和联系人数据导入系统。我们帮助包括 Google 和 Comcast 在内的一些领先的电子邮件和通讯录提供商,通过数据导入自动化切换体验,从而增加用户增长和参与度。
通过将我们的 API 集成到他们的产品中,我们的客户允许他们的用户轻松地将电子邮件和联系人从一个参与的提供商迁移到另一个,减少了用户在切换到新提供商时面临的阻力。我们支持的 24/7 电子邮件提供商包括所有主要的美国互联网服务提供商:Comcast、Time Warner Cable、AT&T、Verizon 等等。
通过为终端用户提供迁移电子邮件的简单路径(同时保持对导入工具用户界面的完全控制),我们的客户显著改善了用户激活和引导过程。
 ShuttleCloud 与 Google Gmail 平台的集成 。 Gmail 已通过我们的 API 为 300 万用户导入了数据。
ShuttleCloud 与 Google Gmail 平台的集成 。 Gmail 已通过我们的 API 为 300 万用户导入了数据。
ShuttleCloud 的技术对处理导入所需的所有数据进行加密,并遵循最安全标准(SSL、oAuth),以确保 API 请求的机密性和完整性。我们的技术使我们能够保证平台的高可用性,正常运行时间保证高达 99.5%。

在使用 Prometheus 之前,您的监控体验是怎样的?
最初,为我们的基础设施建立一个合适的监控系统并不是我们的主要优先事项之一。那时我们的项目和实例数量没有现在这么多,所以我们使用其他简单的系统来提醒我们是否有任何问题,并将其控制在可控范围内。
- 我们有一套自动脚本来监控机器的大部分操作指标。这些脚本基于 cron,并使用 Ansible 从一台中心机器执行。警报是直接发送给整个开发团队的邮件。
- 我们信任 Pingdom 进行外部黑盒监控,检查我们所有的前端是否正常运行。他们提供了一个简单的界面和警报系统,以防我们的任何外部服务无法访问。
幸运的是,大客户来了,服务等级协议(SLA)的要求也越来越高。因此,我们需要别的东西来衡量我们的表现,并确保我们遵守所有的 SLA。我们要求的功能之一是能够准确统计我们的性能和业务指标(例如,有多少迁移正确完成),所以我们更关心报告而不是监控。
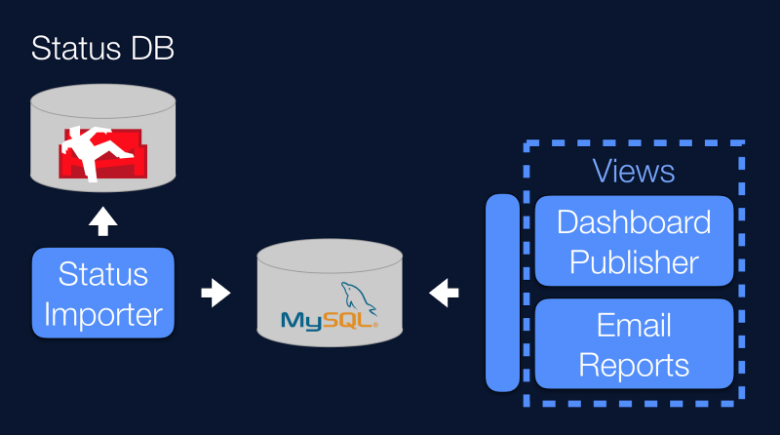
我们开发了以下系统
-
所有必要数据的来源是 CouchDB 中的一个状态数据库。其中,每个文档代表一个操作的状态。这些信息由 Status Importer 处理,并以关系型方式存储在 MySQL 数据库中。
-
一个组件从该数据库收集数据,并将聚合和后处理的信息整合到几个视图中。
- 其中一个视图是电子邮件报告,我们用于报告目的。这是通过电子邮件发送的。
- 另一个视图将数据推送到仪表盘,在那里可以轻松地进行控制。我们使用的仪表盘服务是外部的。我们信任 Ducksboard,不仅因为仪表盘易于设置且外观精美,还因为如果达到阈值,它们会提供自动警报。
有了这一切,我们很快就意识到,随着项目数量的增加,我们将需要一个合适的指标、监控和警报系统。
我们当时系统的一些缺点是
- 没有集中的监控系统。每种指标类型都有一个不同的系统
- 系统指标 → 由 Ansible 运行的脚本。
- 业务指标 → Ducksboard 和电子邮件报告。
- 黑盒指标 → Pingdom。
- 没有标准的警报系统。每种指标类型都有不同的警报(电子邮件、推送通知等)。
- 一些业务指标没有警报。这些是手动审查的。
你们为什么决定研究 Prometheus?
我们分析了几个监控和警报系统。我们渴望亲自动手,检验一个解决方案是成功还是失败。我们决定测试的系统是 Prometheus,原因如下
- 首先,你不需要定义一个固定的指标系统就可以开始使用它;指标可以在未来添加或更改。当您还不清楚所有想要监控的指标时,这提供了宝贵的灵活性。
- 如果您对 Prometheus 有所了解,您就知道指标可以有标签,这使我们不必考虑不同的时间序列。这一点,再加上它的查询语言,提供了更大的灵活性和强大的工具。例如,我们可以为不同的环境或项目定义相同的指标,并使用适当的标签获取特定的时间序列或聚合某些指标
http_requests_total{job="my_super_app_1",environment="staging"}- 对应于“my_super_app_1”应用的预发布(staging)环境的时间序列。http_requests_total{job="my_super_app_1"}- “my_super_app_1”应用所有环境的时间序列。http_requests_total{environment="staging"}- 所有作业的所有预发布(staging)环境的时间序列。
- Prometheus 支持 DNS 服务进行服务发现。我们碰巧已经有了一个内部 DNS 服务。
- 无需安装任何外部服务(不像 Sensu,它需要像 Redis 这样的数据存储服务和像 RabbitMQ 这样的消息总线)。这可能不是决定性因素,但它无疑使测试、部署和维护变得更容易。
- Prometheus 安装相当容易,因为你只需要下载一个可执行的 Go 文件。Docker 容器也运行得很好,并且很容易启动。
你们如何使用 Prometheus?
最初,我们只使用 node_exporter 开箱即用提供的一些指标,包括
- 硬盘使用情况。
- 内存使用情况。
- 实例是启动还是关闭。
我们的内部 DNS 服务已集成用于服务发现,因此每个新实例都会被自动监控。
我们使用的一些不由 node_exporter 默认提供的指标,是使用 node_exporter 的文本文件收集器 功能导出的。我们在 Prometheus Alertmanager 上声明的第一批警报主要与上述操作指标有关。
我们后来开发了一个操作导出器,让我们能几乎实时地了解系统状态。它暴露了业务指标,即所有操作的状态、传入迁移的数量、完成迁移的数量以及错误数量。我们可以在 Prometheus 端聚合这些数据,并让它计算不同的速率。
我们决定导出并监控以下指标
operation_requests_total (操作请求总数)operation_statuses_total (操作状态总数)operation_errors_total (操作错误总数)
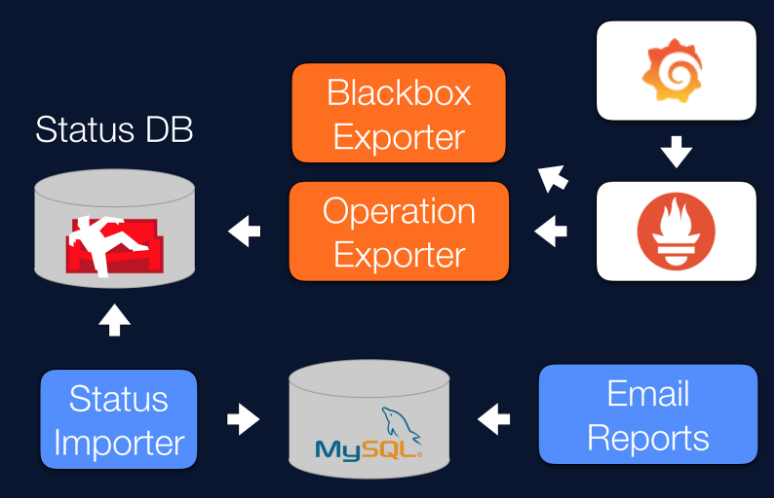
我们的大部分服务在两个 Google Cloud Platform 可用区都有副本。这包括监控系统。在两个或更多不同区域拥有多个操作导出器是很直接的,因为 Prometheus 可以聚合所有这些数据并生成一个指标(例如,所有指标的最大值)。我们目前没有高可用(HA)的 Prometheus 或 Alertmanager——只有一个元监控实例——但我们正在努力实现它。
对于外部黑盒监控,我们使用 Prometheus Blackbox Exporter 。除了检查我们的外部前端是否正常运行外,它在获取 SSL 证书到期日期的指标方面特别有用。它甚至会检查整个证书链。感谢 Robust Perception 在他们的博文 中完美地解释了这一点。
我们在 Grafana 中为一些仪表盘设置了一些图表用于可视化监控,与 Prometheus 的集成非常简单。用于定义图表的查询语言与 Prometheus 中的相同,这极大地简化了它们的创建。
我们还将 Prometheus 与 Pagerduty 集成,并为关键警报创建了待命人员排班表。对于那些不被认为是关键的警报,我们只发送电子邮件。
Prometheus 如何让你们的工作变得更好?
我们无法将 Prometheus 与我们之前的解决方案进行比较,因为我们没有一个,但我们可以谈谈 Prometheus 的哪些功能对我们来说是亮点
- 它的维护要求非常少。
- 它效率很高:一台机器就可以处理整个集群的监控。
- 社区很友好——包括开发者和用户。此外,Brian 的博客 是一个非常好的资源。
- 它没有第三方依赖;只有服务器和导出器。(无需维护 RabbitMQ 或 Redis。)
- Go 应用程序的部署非常轻松。
您认为 ShuttleCloud 和 Prometheus 的未来会怎样?
我们对 Prometheus 非常满意,但新的导出器总是受欢迎的(例如,Celery 或 Spark)。
每次我们添加新警报时都会面临一个问题:我们如何测试该警报是否按预期工作?如果能有一种方法注入虚假指标以触发警报,从而进行测试,那就太好了。