监控 DreamHack——全球最大的数字节
2015 年 6 月 24 日作者 Christian Svensson (DreamHack 网络团队)
编者注:本文是一位 Prometheus 用户撰写的客座文章。
如果你在为成千上万要求苛刻的游戏玩家运营网络,你需要真正了解网络内部发生了什么。哦,还有,所有东西都必须在短短五天内从零开始搭建。
如果你从未听说过 DreamHack ,这里简单介绍一下:将 20,000 人聚集在一起,让他们中的大多数人带上自己的电脑。再混合上职业游戏(电子竞技)、编程比赛和现场音乐会。其结果就是这个全球最大的、完全专注于一切数字事物的节日。
要使这样的活动成为可能,需要大量的基础设施。建设如此规模的普通基础设施需要数月时间,但 DreamHack 的工作人员在短短五天内就从零开始搭建好了一切。这当然包括配置网络交换机等工作,但也包括搭建电力分配系统、为食品和饮料设立商店,甚至还包括搭建实际的桌子。
负责构建和运营所有与网络相关事务的团队官方名称是“网络团队”,但我们通常称自己为 tech 或 dhtech。这篇文章将重点介绍 dhtech 的工作,以及我们如何在 2015 年 DreamHack 夏季赛期间使用 Prometheus,试图将我们的监控水平提升到一个新高度。
设备
事实证明,要为 10,000 多台计算机搭建一个高性能网络,你至少需要同样数量的网络端口。在我们的案例中,这些端口以约 400 台思科 2950 交换机的形式出现。我们称之为主接入交换机。它们遍布在场馆内参与者将带着电脑就座的任何地方。

显然,仅仅将所有这些计算机连接到一台交换机是不够的。这台交换机也需要连接到其他交换机。这时,汇聚交换机(或称 dist switches)就派上用场了。这些交换机将来自所有接入交换机的数百条链路汇聚成更易于管理的 10-Gbit/s 高容量光纤。然后,汇聚交换机再进一步汇聚到我们的核心网络,流量在那里被路由到其目的地。
除此之外,我们还运营自己的 WiFi 网络、DNS/DHCP 服务器以及其他基础设施。完成后,我们的核心网络看起来如下图所示。
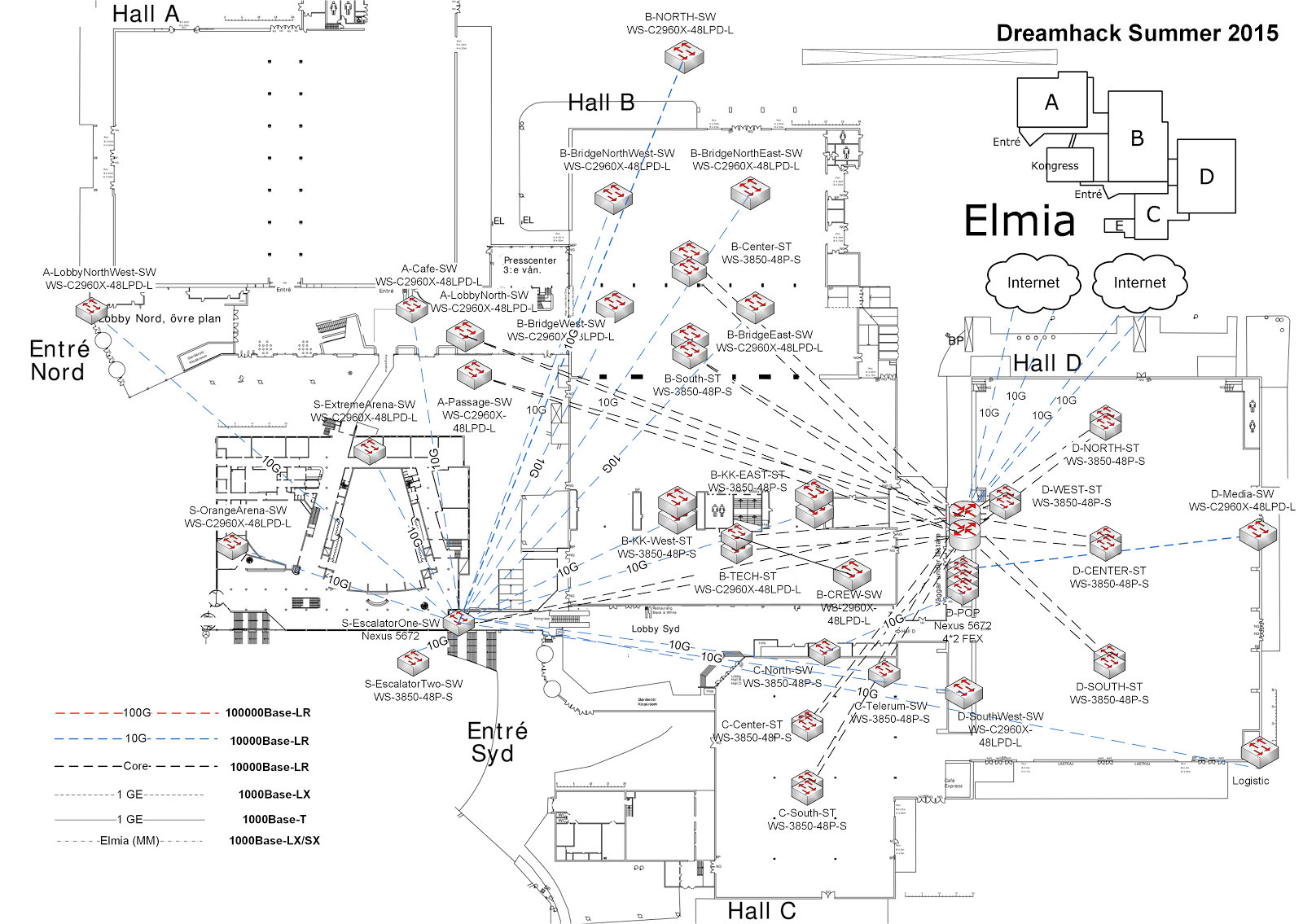
总而言之,这成了一个需要监控的长长清单,所以让我们进入你来此的原因:我们如何确保自己了解正在发生什么?
介绍:dhmon
dhmon 是一个系统的统称,它不仅监控网络,还允许其他团队收集他们想要的任何指标。
由于网络需要在五天内搭建完成,因此监控系统必须易于设置,并且在我们需要进行最后一刻的基础设施变更(如添加或移除设备)时保持同步,这一点至关重要。当我们开始搭建网络时,我们需要尽快启动监控,以便能够发现设备存在的任何问题或其他我们未预见到的问题。
过去,我们曾尝试使用 Cacti、SNMPc 和 Opsview 等常见软件的混合体。虽然这些软件也能用,但它们都专注于成为封闭系统,并且只提供最基本的功能。几年前,团队中的几个人说:“够了,我们自己能做得更好!”然后开始编写一个自定义的监控解决方案。
当时的选择有限。多年来,该系统从使用 Graphite(可扩展性问题)、自定义的 Cassandra 存储(高复杂度)和 InfluxDB(软件不成熟),最终落定于使用 Prometheus。我第一次了解 Prometheus 是在 2014 年,当时我遇到了 Julius Volz,从那以后就一直渴望尝试它。今年夏天,我们终于用 Prometheus 替换了我们自己编写的基于 InfluxDB 的指标存储。剧透一下:我们不打算回头了。
架构
监控解决方案由三个层次组成:收集、存储、展示。我们最关键的收集器是 snmpcollector (SNMP) 和 ipplan-pinger (ICMP),紧随其后的是 dhcpinfo(DHCP 租约统计)。我们还有一些脚本,将其他系统的统计数据转储到 node_exporter 的文本文件收集器中。
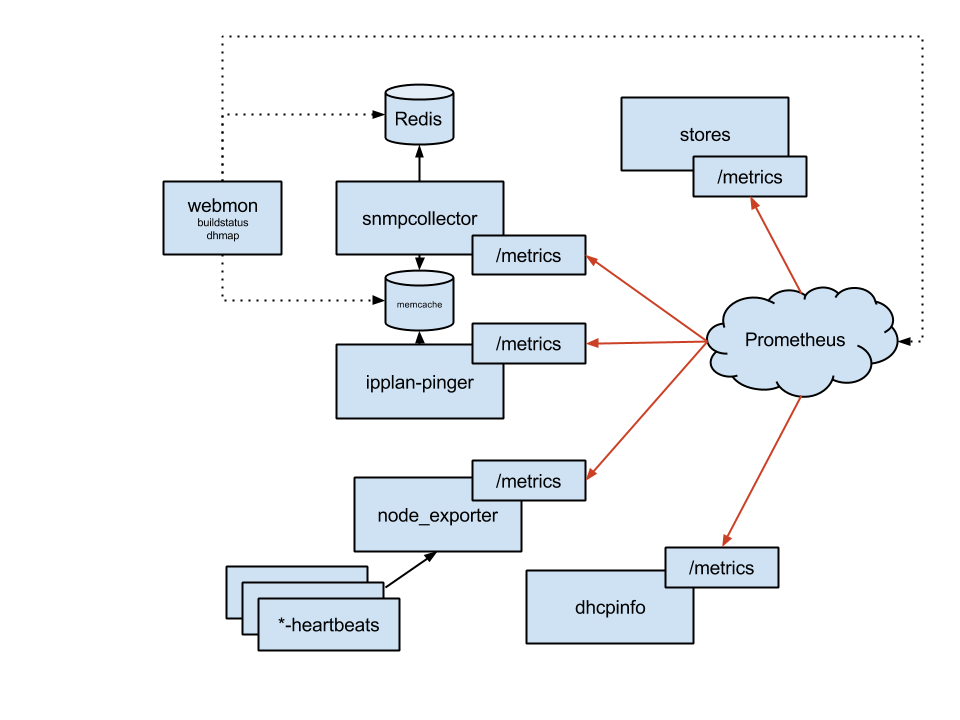
我们使用 Prometheus 作为中央时间序列存储和查询引擎,但我们也使用 Redis 和 memcached 来导出我们收集但无法以任何合理方式存储在 Prometheus 中的二进制信息的快照视图,或者当我们需要访问非常新的数据时。
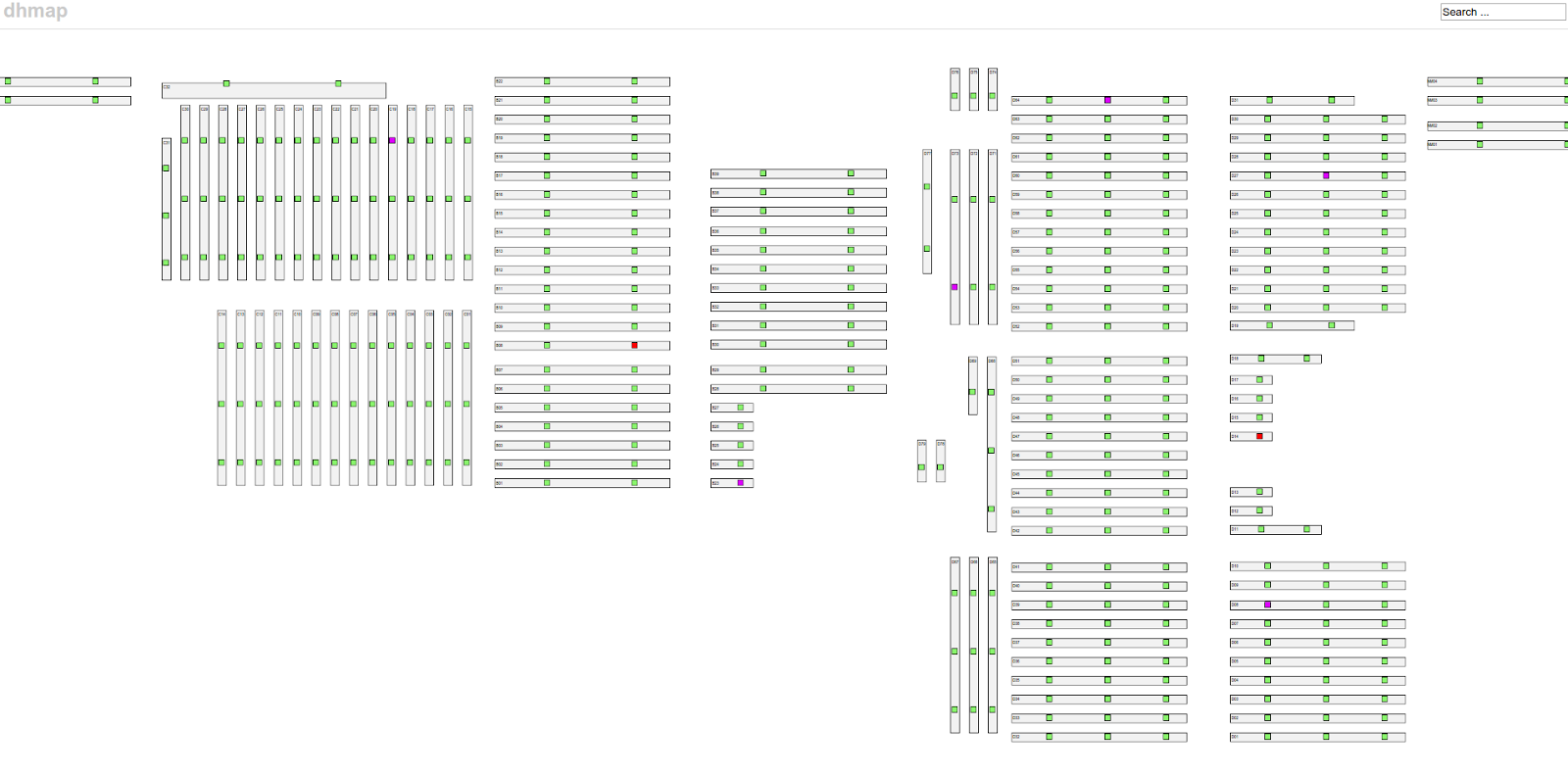
其中一个案例是在我们的展示层。我们使用 dhmap Web 应用程序来概览接入交换机的整体健康状况。为了有效地解决错误,我们需要从数据收集到展示的延迟约为 10 秒。我们的目标是在客户注意到问题之前就解决问题,或者至少在他们走到支持人员那里报告问题之前。因此,我们从一开始就使用 memcached 来访问网络的最新快照。
今年我们继续使用 memcached 来处理低延迟数据,同时将 Prometheus 用于所有历史数据或对延迟不那么敏感的数据。这个决定仅仅是因为我们不确定 Prometheus 在非常短的采样间隔下的性能如何。最终,我们发现没有任何理由不能将 Prometheus 用于这些数据——我们肯定会在下一次 DreamHack 上尝试用 Prometheus 替换我们的 memcached。
Prometheus 设置
到目前为止被称为 Prometheus 的模块实际上由三个产品组成:Prometheus 、PromDash 和 Alertmanager 。这个设置相当基础,所有三个组件都运行在同一台主机上。所有服务都由一个仅作为反向代理的 Apache Web 服务器提供。
ProxyPass /prometheus https://:9090/prometheus
ProxyPass /alertmanager https://:9093/alertmanager
ProxyPass /dash https://:3000/dash
探索网络
Prometheus 有一个强大的查询引擎,可以让你用从网络各处收集到的流式信息做一些非常酷的事情。然而,有时查询需要处理太多数据,无法在合理的时间内完成。当我们想要绘制出总共约 18,000 个链路中利用率最高的 5 个时,就遇到了这种情况。虽然查询能工作,但它大约需要我们设置的超时限制那么长的时间,这意味着它既慢又不稳定。我们决定使用 Prometheus 的记录规则来预计算这些繁重的查询。
precomputed_link_utilization_percent = rate(ifHCOutOctets{layer!='access'}[10m])*8/1000/1000
/ on (device,interface,alias)
ifHighSpeed{layer!='access'}
之后,运行 topk(5, precomputed_link_utilization_percent) 就快如闪电了。
被动响应:告警
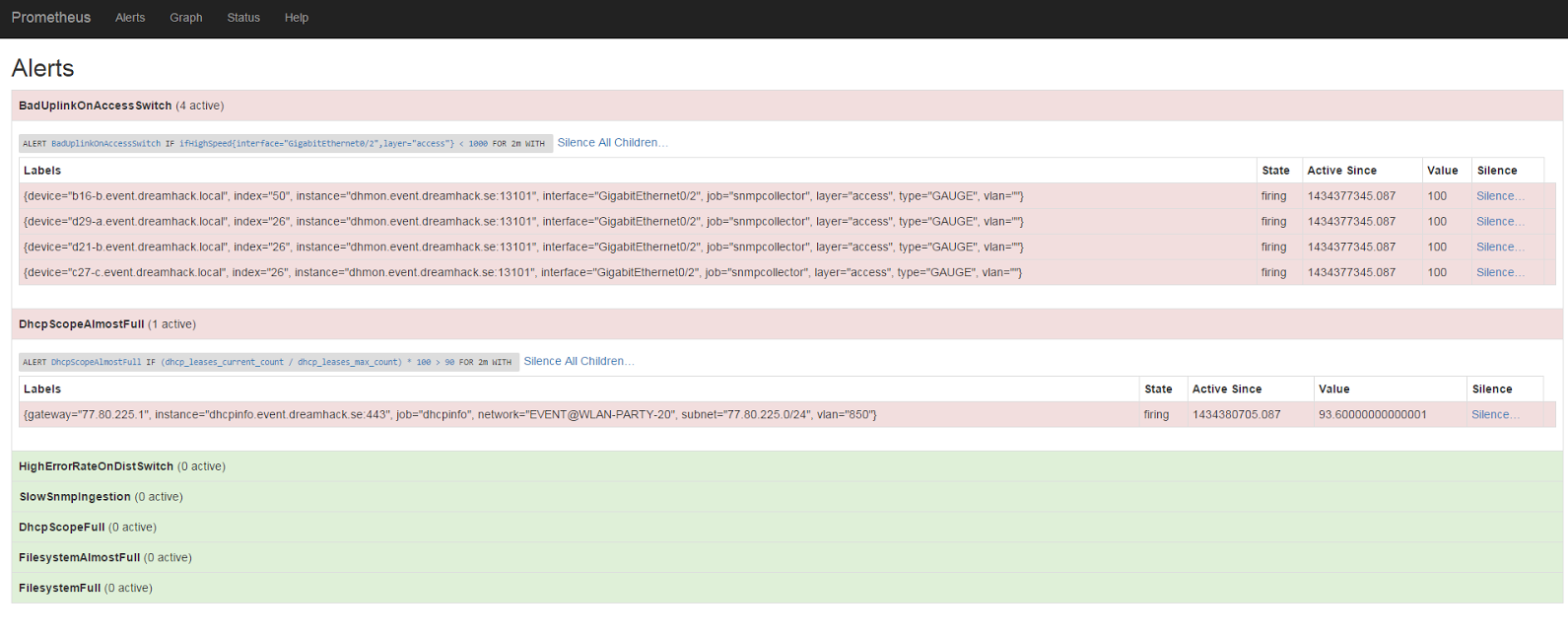
所以到了这个阶段,我们有了一个可以查询网络状态的系统。因为我们是人类,不想花时间一直运行查询来检查系统是否仍在正常运行,所以我们显然需要告警。
例如:我们知道我们所有的接入交换机都使用 GigabitEthernet0/2 作为上行链路。有时当网线存放太久后,它们会氧化,无法协商到我们想要的完整 1000 Mbps 速度。
网络端口的协商速度可以在 SNMP OID IF-MIB::ifHighSpeed 中找到。然而,熟悉 SNMP 的人会意识到这个 OID 是由一个任意的接口索引来索引的。为了理解这个索引的意义,我们需要将它与来自 SNMP OID IF-MIB::ifDescr 的数据进行交叉引用,以获取实际的接口名称。
幸运的是,我们的 snmpcollector 在生成 Prometheus 指标时支持这种交叉引用。这使我们能够以一种简单的方式不仅查询数据,还能定义有用的告警。在我们的设置中,我们将 SNMP 收集配置为使用 ifDescr 来注解 IF-MIB::ifTable 和 IF-MIB::ifXTable OID 下的任何指标。这在我们现在需要指定只关心 GigabitEthernet0/2 端口而不管其他接口时就派上了用场。
让我们看看这样一个告警定义是什么样子的。
ALERT BadUplinkOnAccessSwitch
IF ifHighSpeed{layer='access', interface='GigabitEthernet0/2'} < 1000 FOR 2m
SUMMARY "Interface linking at {{$value}} Mbps"
DESCRIPTION "Interface {{$labels.interface}} on {{$labels.device}} linking at {{$value}} Mbps"
完成了!现在,如果一个交换机的上行链路突然以非最佳速度连接,我们就会收到一个告警。
我们再来看看一个关于 DHCP 作用域几乎满的告警是什么样子的。
ALERT DhcpScopeAlmostFull
IF ceil((dhcp_leases_current_count / dhcp_leases_max_count)*100) > 90 FOR 2m
SUMMARY "DHCP scope {{$labels.network}} is almost full"
DESCRIPTION "DHCP scope {{$labels.network}} is {{$value}}% full"
我们发现,即使你之前没有使用 Prometheus 或时间序列数据库的经验,定义告警的语法也易于阅读和理解。
主动预防:仪表盘
虽然告警是监控的重要组成部分,但有时你只是想对网络的健康状况有一个很好的概览。为了实现这一点,我们使用了 PromDash。每次有人问我们关于网络的问题时,我们都会精心制作一个查询来得到答案,并将其保存为一个仪表盘小部件。然后将最有趣的那些添加到一个概览仪表盘中,我们自豪地展示它。
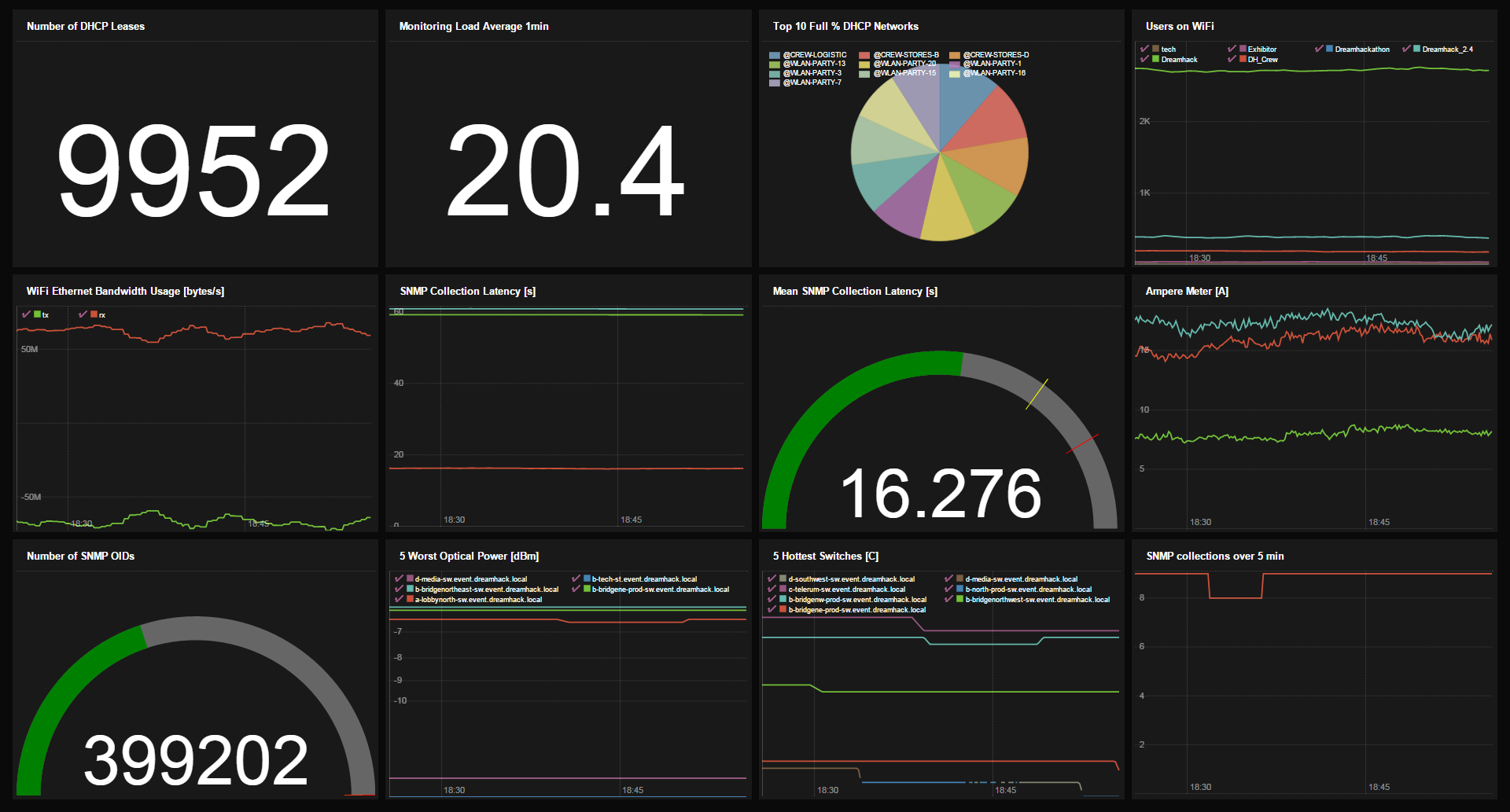
未来
虽然改变任何系统的核心部分是一项复杂的工作,我们很高兴能在一个活动中就成功集成了 Prometheus,但毫无疑问还有很多地方需要改进。一些领域相当基础:使用更多预计算的指标来提高性能,添加更多告警,以及调整我们现有的告警。另一个领域是让操作员更方便:创建一个适合我们网络运营中心(NOC)的告警仪表盘,弄清楚我们是想呼叫待命人员,还是让 NOC 来升级告警。
我们计划添加的一些更大功能包括:syslog 分析(我们有大量的 syslog!)、来自我们入侵检测系统的告警、与我们的 Puppet 设置集成,以及在 DreamHack 的不同团队之间进行更多集成。我们成功创建了一个概念验证,将其中一个电流传感器的数据输入到我们的监控系统中,这样就可以很容易地看出一个设备是故障了,还是仅仅是断电了。我们还在努力与活动现场商店使用的销售点系统集成。谁不想绘制冰淇淋销售的图表呢?
最后,并非团队运营的所有服务都在现场,有些甚至在活动结束后 24/7 运行。我们也想用 Prometheus 来监控这些服务,并且从长远来看,当 Prometheus 支持联邦时,利用非现场的 Prometheus 来复制活动现场 Prometheus 的指标。
结束语
我们对 Prometheus 及其能如此轻松地从零开始搭建可扩展的监控和告警系统感到非常兴奋。
非常感谢在活动期间 FreeNode 上 #prometheus 频道帮助过我们的每一个人。特别感谢 Brian Brazil、Fabian Reinartz 和 Julius Volz。感谢你们的帮助,即使是在我们明显没有仔细阅读文档的情况下。
最后,dhmon 是完全开源的,所以如果你感兴趣,请访问 https://github.com/dhtech/ 看一看。如果你觉得想成为其中的一员,就到 QuakeNet 上的 #dreamhack 频道和我们聊聊。谁知道呢,也许你会帮助我们搭建下一届 DreamHack?